A Layer-wise Probing on BERToids’ Representations
Published:
EMNLP 2021 (BlackboxNLP)
In this work, we extend the probing studies to ELECTRA and XLNet, showing that variations in pre-training objectives can result in different behaviors in encoding linguistic information. We show that
- Weight mixing results in edge probing does not lead to reliable conclusions in layer-wise cross model analysis studies and MDL probing is more informative in this setup.
- XLNet accumulates linguistic knowledge in the earlier layers than BERT, whereas that of ELECTRA is in the final layers.
- ELECTRA undergoes a slight change during fine-tuning, whereas XLNet experiences significant adjustments.
read more read paper poster
1. What is probing?
 With the impressive success of pre-trained language models, such as BERT, and their significant advances in transfer learning, a wave of interest has recently been directed toward understanding the knowledge encoded in their representations. One of the analytical tools which is widely used for this investigation is probing: training a shallow supervised classifier that attempts to predict specific linguistic properties or reasoning abilities, based on representations obtained from the model
With the impressive success of pre-trained language models, such as BERT, and their significant advances in transfer learning, a wave of interest has recently been directed toward understanding the knowledge encoded in their representations. One of the analytical tools which is widely used for this investigation is probing: training a shallow supervised classifier that attempts to predict specific linguistic properties or reasoning abilities, based on representations obtained from the model
⚠️ Edge probing “scalar mixing weights” reliability issues
To estimate the contribution of each layer to a given probing task, Tenney et al. (2019) used a technique called scalar mixing weights which associates a trainable scalar weight with each layer in the model. After learning these weights alongside the probing classifier, they interpret layers with higher weights as those having more information for the particular task.
While Tenney et al. (2019) made interesting conclusions on BERT using edge probing and the scalar mixing weights evaluation strategy, we argue that this procedure is not reliable for layer-wise comparison. Several recent studies have conducted their experiments based on edge probing and weight mixing evaluation strategy. In one such study, Toshniwal et al. (2020) concluded that XLNet relies heavily on the input embedding layer in mixing weight evaluation for the coreference arc prediction task. 
We show that this conclusion might not be accurate given that the representation norms in XLNet drastically change throughout layers. In XLNet, the norm of the embedding layer is extremely smaller than that of other layers. This clearly shows that the concentration of edge probing’s weight on the embedding layer does not indicate the level of information encoded in that layer. Rather, the model tries to compensate for relatively small representation norms in XLNet’s first layer. On the contrary, BERT retains the same level of representation norms across different layers. However, even such minor differences in representation norms might affect the conclusions of edge probing.
A better choice: MDL Probing
Conventional probes leave unclear whether the classifier identifies linguistic knowledge in the representations or learns the task itself. Voita and Titov (2020) combined the final quality of the probe classifier and the difficulty of achieving it by reformulating probes to a data transmission problem and introducing Minimum Description Length Probing.
As the MDL probe is more stable and informative than other conventional probes, one can compare the codelength across layers of the same model or different models for a given probing task. The edge probing method does not allow this comparison since the mixing weights do not necessarily provide an accurate estimate of the richness of linguistic knowledge within each layer. In contrast, in MDL probing, each layer is probed separately, which gives us a direct estimate of the quality of the specific layer itself, rather than that relative to the other layers. MDL probing is, therefore, a better choice to have a layer-wise comparison among different models.
For better interpretability, instead of codelength, we employ compression defined as:
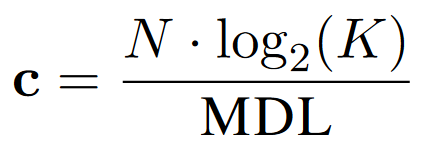
Larger compression means encoding more information related to the particular probing task.
See this post for more information.
2. Probing Pre-trained Representations
Overall comparison
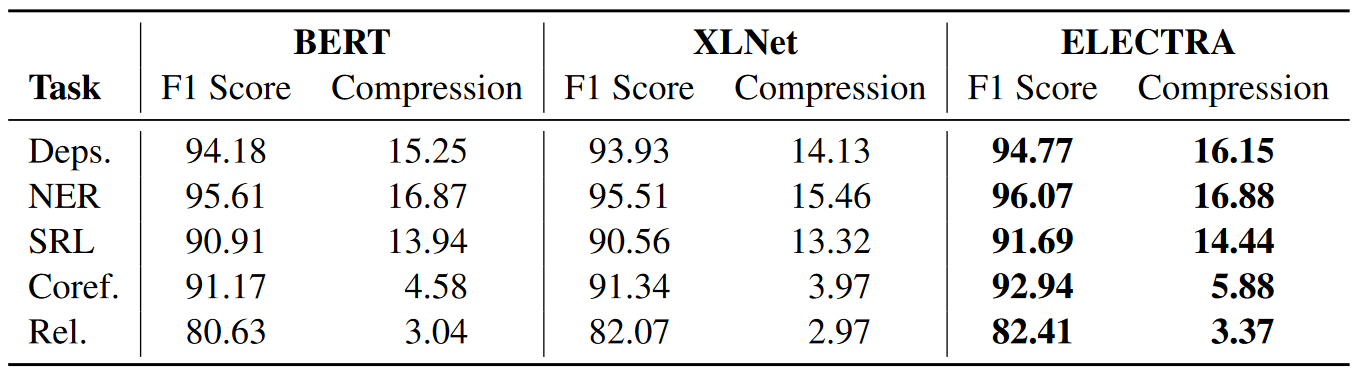
For an overall cross-model comparison, we report the MDL probe compression (Best among layers) and edge probing F1 score results. Both results demonstrate how well the five tasks are encoded in the models’ representations during pre-training. ELECTRA seems to have the best pre-training objective for incorporating linguistic knowledge among the three models. On the other hand, XLNet displays comparable results to BERT, which is interesting given the relatively better fine-tuned performance of the former in a variety of downstream tasks.
Layer-wise analysis
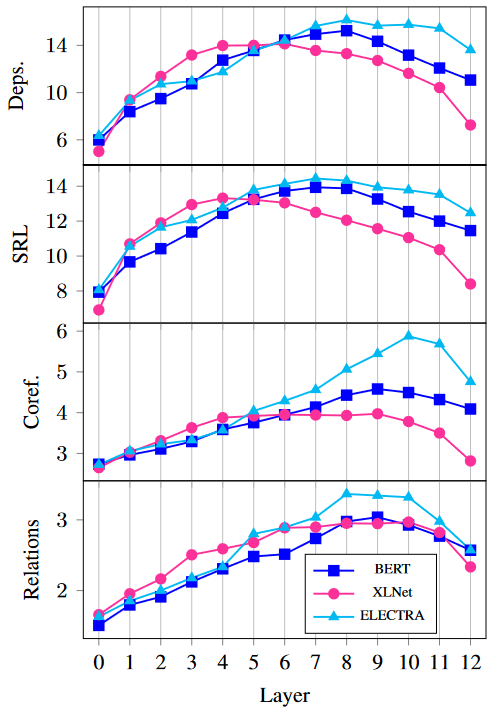 Next, we use MDL probing to investigate how much linguistic knowledge is encoded in different layers in these models. Based on layer-wise MDL probing compression results, ELECTRA attains the highest compression in different layers across most tasks, especially in the deeper layers. Notably, all models start with relatively low compressions and reach higher values in their middle layers. An interesting behavior shared among the three models is the decrease towards the final layer, which can be attributed to their pre-training objectives.
Next, we use MDL probing to investigate how much linguistic knowledge is encoded in different layers in these models. Based on layer-wise MDL probing compression results, ELECTRA attains the highest compression in different layers across most tasks, especially in the deeper layers. Notably, all models start with relatively low compressions and reach higher values in their middle layers. An interesting behavior shared among the three models is the decrease towards the final layer, which can be attributed to their pre-training objectives.
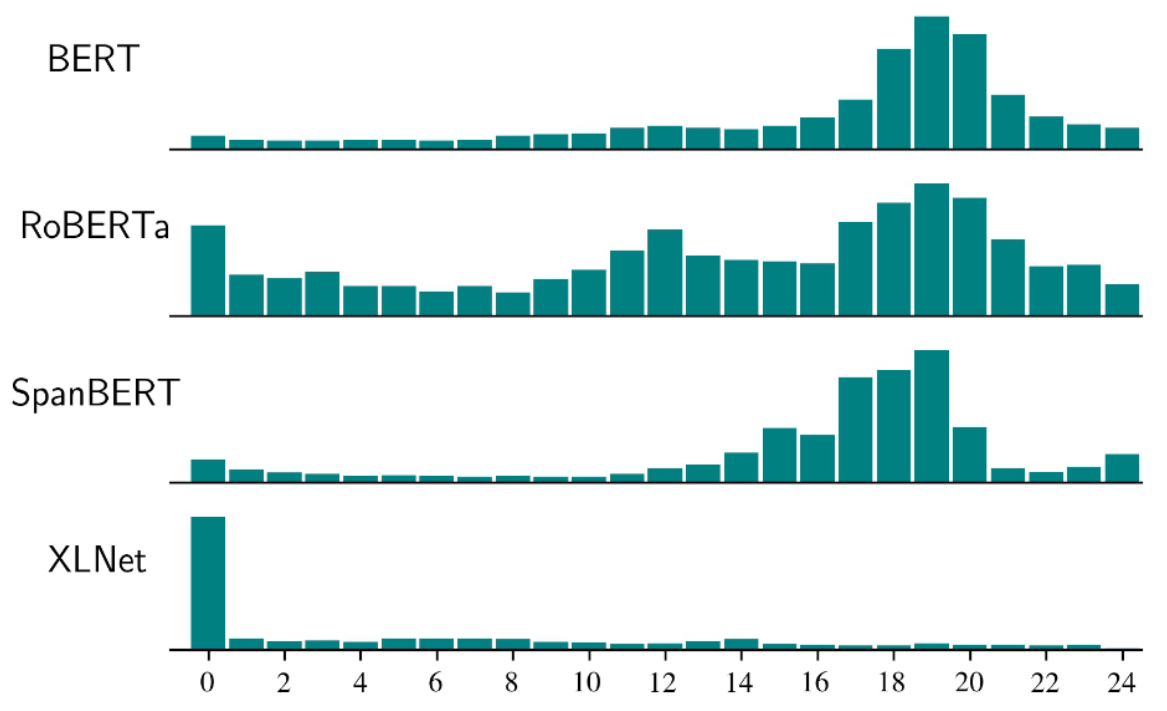
To better demonstrate the layer that most captures each task, we compute the center of gravity, and apply it on MDL probing compression, defined as:
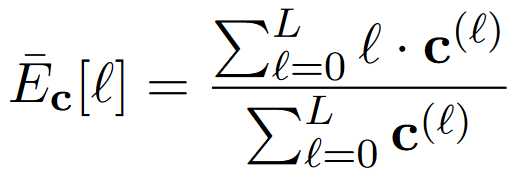
where $\mathbf{c}^{(\ell)}$ is the compression score of layer $\ell$.
The most noticeable distinction among models is that XLNet’s linguistic knowledge is concentrated in earlier layers than BERT, while ELECTRA’s knowledge is mostly accumulated in deeper layers. 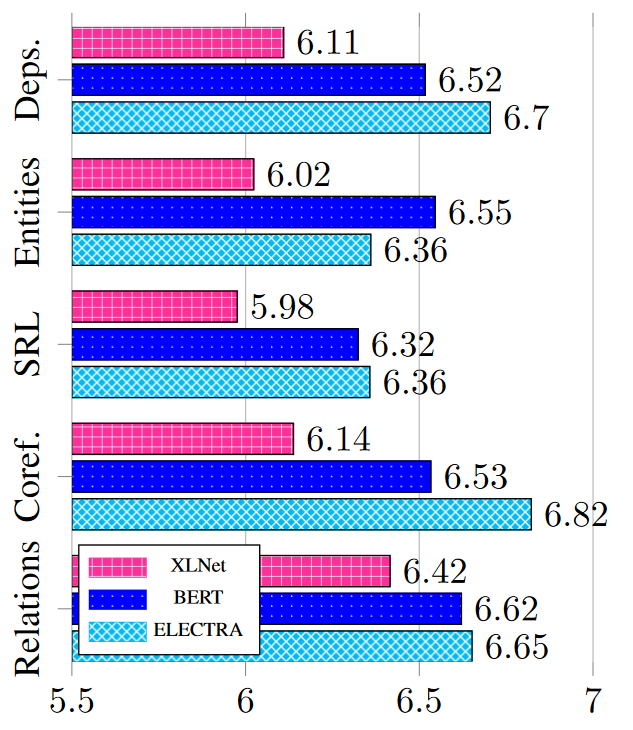
We hypothesize that the difficulty of the objectives has a direct effect on the expected position with the most encoded linguistic knowledge. In particular, recovering input tokens in the final layers of the model in the pre-training objective of BERT and XLNet is a surface task. Some of the linguistic knowledge might diminish in the final layers since highly contextualized representations have to be transformed into a less contextualized level to predict the original inputs. Whereas the pre-training objective in ELECTRA might be considered as a more semantic task, in which detecting replaced tokens requires more context-aware representations.
3. Probing Fine-tuned Representations
Center of Gravity in fine-tuned models
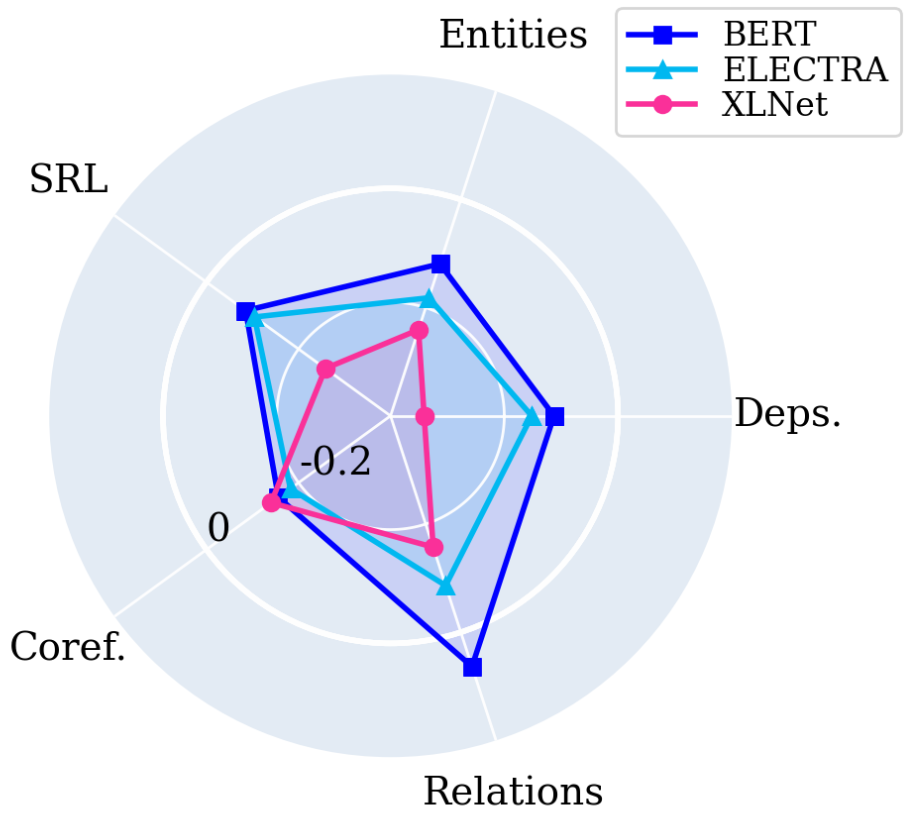 We measure the difference of the two centers of gravity to evaluate the extent to which the concentration of knowledge shifts for each model on a specific probing task after fine-tuning:
We measure the difference of the two centers of gravity to evaluate the extent to which the concentration of knowledge shifts for each model on a specific probing task after fine-tuning:

First, we show that the concentration of information in fine-tuned models is usually in earlier layers compared to the pre-trained models. This can be attributed to the significant loss of linguistic knowledge in the final layers of fine-tuned models in favor of the specific information of the fine-tuning task.
We show that XLNet in most tasks falls back to earlier layers than the two other models because it forgets the most linguistic knowledge in the final layers. This suggests that XLNet is going through a more extensive change in its representations which we investigate in the following sections.
Global RSA
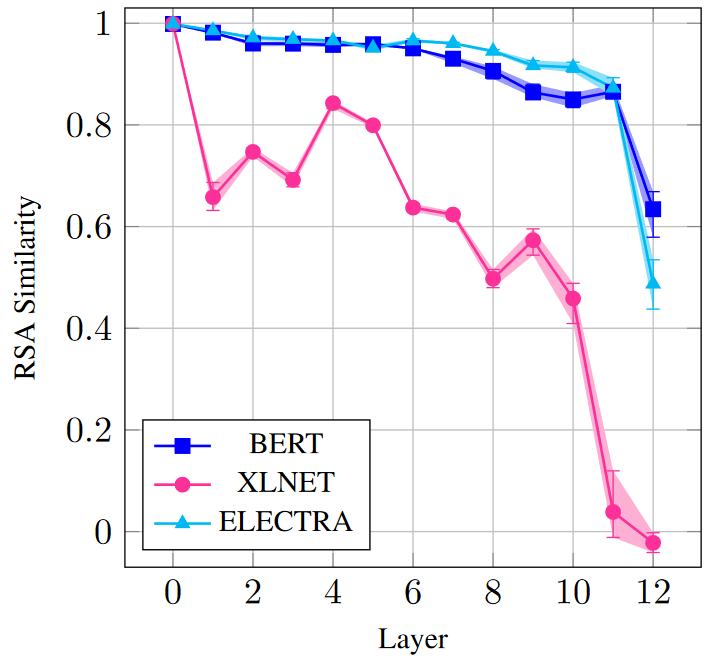
After fine-tuning each model, we leverage Representational Similarity Analysis (RSA) to investigate the overall amount of changes in the representations of each layer.
We observe that XLNet has changed drastically during fine-tuning, while in BERT and ELECTRA, only the top layers are primarily affected. We also see that BERT shows a conservative pattern in the fine-tuning process which is consistent with findings of Merchant et al. (2020).
We hypothesize that higher layers in XLNet are more open to change since they have relatively less specific knowledge. On the contrary, ELECTRA, which enjoys more linguistic information in its representations, especially in the higher layers, does not need to change very much.
Quality of the representations for downstream tasks
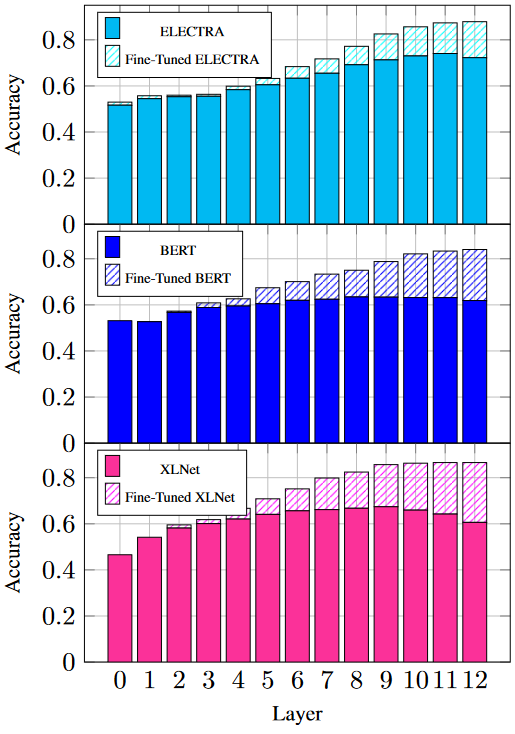 We evaluated the quality of the representations for downstream tasks in both pre-trained and fine-tuned models by training separate classifiers on the unweighted average of representations for each layer.
We evaluated the quality of the representations for downstream tasks in both pre-trained and fine-tuned models by training separate classifiers on the unweighted average of representations for each layer.
Based on the performance scores for pre-trained representations, we observe that XLNet encodes most essential information for the downstream task in the shallower layers, BERT in the middle ones, and ELECTRA in the deeper layers. Interestingly, these patterns are well aligned with the MDL probing curves on core linguistic tasks.
In addition, we show that XLNet significantly improves performance in its second half of layers, while ELECTRA undergoes smaller adjustments.
We observe that, before fine-tuning, the last layers of XLNet have fairly similar or even lower performance than BERT. However, when fine-tuned, XLNet compensates for the performance deficit by injecting more task-specific information in those layers, helping the model to outperform BERT.
Finally, we demonstrate that the changes in layers and their extent are similar to what we saw in the RSA results, which indicates that the changes in RSA were actually made to achieve higher quality in the fine-tuning task.
4. Conclusions
In this paper, we aimed to extend probing studies on BERT to the other models in the family to investigate how training objectives and architectural choices would affect the resulting representations and the linguistic knowledge encoded in them. By probing three state-of-the-art language models, i.e., BERT, XLNet, and ELECTRA, we found considerable differences in the extent and distribution of the core linguistic knowledge in their representations. Specifically, we demonstrate that XLNet accumulates linguistic knowledge in the earlier layers than BERT, whereas that of ELECTRA is mainly in the final layers.
Moreover, from probing and employing RSA similarity measure on fine-tuned models, we illustrate that XLNet is more susceptible to forgetting linguistic knowledge in final layers and undergoes substantial adjustments to its representations when compared to the other models. Based on differential downstream performance observations for before and after fine-tuning, we confirm that the changes in representations are proportional to the provided gain in the downstream task, which consequently indicates that XLNet injects more information during fine-tuning into its representations than the two other models.
In summary, through probing and measurement tools, we demonstrate that BERT’s derivative models, especially those with different objectives and structural choices, express different behaviors in their representations. We hope our analysis helps make more informed choices in the selection and fine-tuning of these state-of-the-art models.
Want to know more? read paper